Um die erwähnte Frage nach der Eignung von ,,strukturierten`` Features für die Klassifikation zu überprüfen, wird in diesem Experiment die bisher verwendete Datenbasis modifiziert. Die XML-Dokumente werden um die enthaltenen Tags reduziert, so daß lediglich die ,,rohen`` Textdaten verbleiben.
Das erste Experiment dieser Reihe wird an den so gewonnen Testdaten durchgeführt. Die Textdokumente werden auf der Basis der ,,manuellen`` Klassen-Zuordnung klassifiziert. Für die Feature-Selektion werden erneut folgende Methoden verwendet:
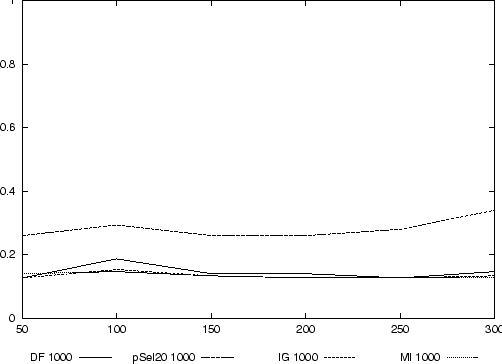
Es zeigt sich, daß auch die Textdokumente mit sehr geringer Precision klassifiziert werden (siehe Abbildung 12), wie es bereits im Experiment mit den entsprechenden XML-Dokumenten der Fall war (siehe Abbildung 6).
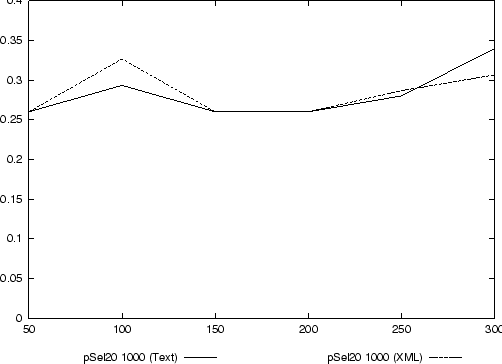
In Abbbildung 13 ist ein direkter Vergleich der p-Selektion mit p=20 für die Klassifikation von Text- bzw. XML-Dokumenten zu sehen. Der Unterschied der Precision ist nur minimal und läßt keine Schlüsse zu, welche der beiden Methoden vorzuziehen ist.
Ergebnis dieses Experiments ist, daß die verwendete Datenbasis offensichtlich nicht für die Aufgabe der Klassifikation geeignet ist, da durch das Weglassen der XML-Tags eine negative Beeinflussung der Klassifikationsqualität durch die ,,strukturierten`` Features ausgeschlossen werden kann. Weiterhin zeigt sich, daß die Verwendung von ,,strukturierten`` Features in diesem Fall genauso gute bzw. schlechte Ergebnisse ermöglicht wie die Klassifikation der korrespondierenden Textdokumente.