Um die aus dem letzten Experiment resultierenden möglichen Fehlerquellen zu untersuchen, wird bei diesem Experiment die eindeutige Zuordnung der Dokumente zu den Klassen als Klassifikationskriterium verwendet.
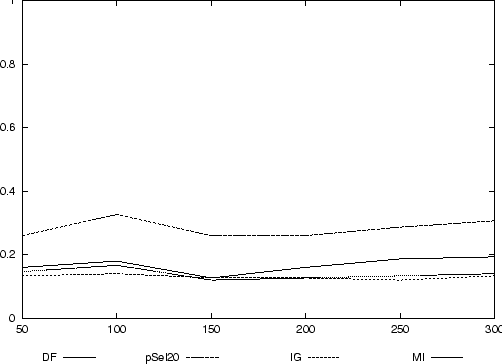
Es werden zunächst 1000 Features mit einfacher Feature-Selektion über absolute Häufigkeit, p-Selektion, IG und MI selektiert.
Im Anschluß daran wird der Klassifikator mit den selektierten Features trainiert und die Testdokumente klassifiziert. Durchgeführt wird dieses Experiment für 50, 100, ..., 300 Trainingsdokumente.
Wie sich in Abbildung 6 zeigt, führt auch die ,,manuelle`` Zuordnung von Dokumenten zu Klassen nicht zu besonders guten Klassifikationsergebnissen, die maximal erreichte Precision ist kleiner als 0,4. Auch hier ist zu beobachten, daß eine größere Menge an Trainingsdaten nicht zu einer besseren Klassifikationsqualität und damit zu einer höheren Precision führt.
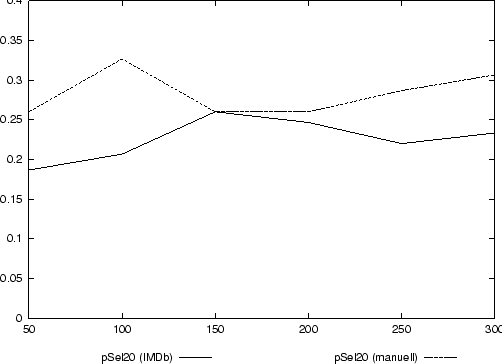
Abbildung 7 zeigt die Ergebnisse der p-Selektion für die verschiedenen Zuordnungen von Dokumenten zu Klassen im Vergleich. Es wird deutlich, daß die eindeutige Zuordnung hierbei zu einem besseren Klassifikationsergebnis führt.
Das Resultat dieses Experiments ist, daß die eindeutige Zuordnung der Dokumente zu den Klassen signifikant bessere Ergebnisse erzielt als die Zuordnung durch die IMDb. Dies war zu erwarten, da die Unterscheidungskriterien zwischen den verschiedenen Klassen durch die ihre Überschneidungen deutlich schwieriger ist. Trotzdem hat sich die Precision nicht so weit verbessert, daß von einer guten bzw. zuverlässigen Klassifikation gesprochen werden kann. Es ist deshalb zunächst herauszufinden, ob der Klassifikator eine gute ,,Lernqualität`` erreicht.