In diesem Experiment wird der Frage nachgegangen, inwieweit sich die mehrdeutige Zuordnung von Dokumenten zu Klassen auf die ,,Lernqualität`` auswirkt. Zum Vergleich mit den zuletzt gewonnen Ergebnissen wird für diese Zuordnung erneut das Experiment der Alternierung von p durchgeführt.
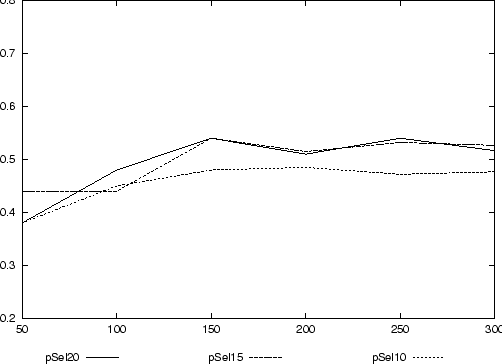
Abbildung 10 zeigt für diesen Fall gegenüber der Klassifikation der Trainingsdaten nach dem eindeutigen Klassen-Zuordnungsschema (siehe Abbildung 9) eine erhebliche Verschlechterung der Qualität der Klassifikation. Precision erreicht hier maximale Werte < 0,6.
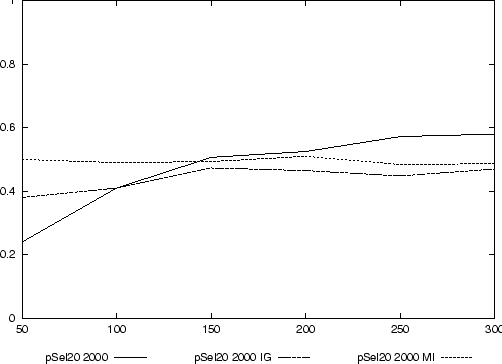
Als nächstes soll überprüft werden, ob dieses Ergebnis durch eine kombinierte Feature-Selektion zu verbessern ist. Es werden zwei Messungen durchgeführt, bei denen jeweils eine Kombination von p-Selektion von 2000 Features mit p=20 und Information Gain bzw. Mutual Information verwendet wird. Die Ergebnisse dieser Selektionen werden mit dem Resultat der einfachen p-Selektion von 2000 Features verglichen.
Das Ergebnis für dieses Experiment zeigt Abbildung 11. Es zeichnet sich deutlich ab, daß die weitergehende Selektion durch IG bzw. MI die Klassifikationsqualität für eine geringe Menge von Trainingsdokumenten verbessern kann, für größere Mengen von Dokumenten jedoch die Qualität der Klassifikation sogar verschlechtern.
In diesem Experiment hat sich eindeutig herausgestellt, daß die ,,Lernqualität`` für die mehrdeutig zu den Klassen zugeordnete Dokumentenmenge schlechter ist als diejenige für die eindeutige Zuordnung, was auch der Erwartung gemäß der schwierigeren Unterscheidung der Klassen entspricht. Da die ,,Lernqualität`` des Klassifikators sich zumindest für die p-Selektion als zuverlässig erwiesen hat, stellt sich nun die Frage, ob die Wahl von ,,strukturierten`` Features der Grund für die schlechte Klassifikation von unbekannten Daten ist.