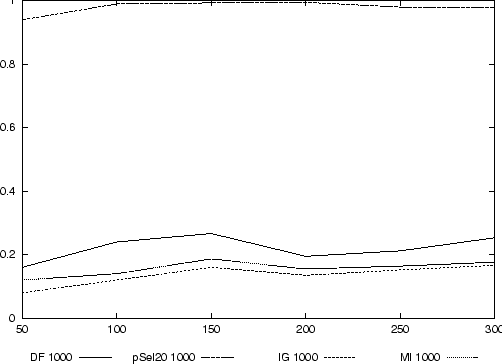
Als letztes Experiment dieser Reihe wird eine Klassifikation der Trainingsdaten vorgenommen, um auch für die Textdaten die ,,Lernqualität`` des Klassifikators zu ermitteln. Basis für diese Messung ist weiterhin die Zuordnung von Dokumenten zu Klassen nach dem ,,manuellen`` Schema. Über die einfache Feature-Selektion von 1000 Features durch die vier verwendeten Methoden werden die Features der Trainingsdaten selektiert, mit denen der Klassifikator trainiert wird, der anschließend die trainierten Daten klassifiziert.
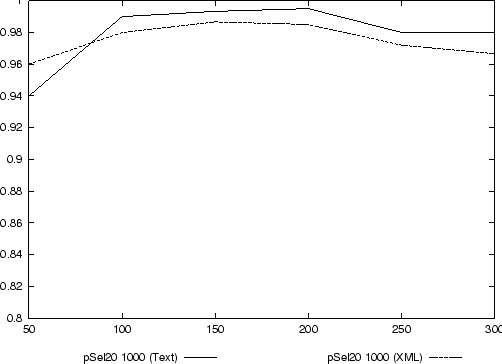
Auch in diesem Fall zeigt sich, daß nur die p-Selektion zu einem guten Klassifikationsergebnis mit einer Precision > 0,95 führt, während die anderen Feature-Selektionsmethoden Precision < 0,4 zur Folge haben. Im Vergleich zwischen der Klassifikation von Textdokumenten und der von XML-Dokumenten (siehe Abbildung 15) zeigt sich, daß beide Konzepte der Textrepräsentation zu ähnlich guten Ergebnissen führen.
Auch die Klassifikation der Trainingsdatenbasis bestätigt die Annahme, das zumindest die Verwendung von ,,strukturierten`` Features nicht Grund der schlechten Klassifikationsqualität ist.
Angesichts der erhobenen Daten ergeben sich folgende mögliche Erklärungen: