Um die ,,Lernqualität`` des Naive-Bayes-Klassifikators zu überprüfen, wird in diesem Experiment die Trainingsdatenbasis sowohl trainiert als auch klassifiziert. Als Grundlage der Klassifikation wird die eindeutige ,,manuelle`` Zuordnung von Dokumenten zu Klassen verwendet.
Der Klassifikator wird mit aufsteigender Anzahl an Trainingsdaten von 50 ausgehend in 50er Schritten bis 300 trainiert wie zuvor.
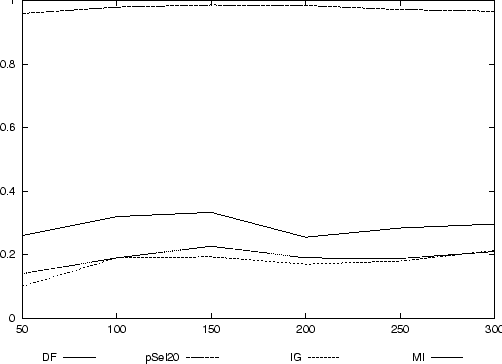
Abbildung 8 zeigt das Ergebnis der Klassifikation nach oben genanntem Schema mit vorheriger Feature-Selektion durch absolute Häufigkeit, p-Selektion, IG und MI von jeweils 1000 Features. Es zeigt sich deutlich, daß lediglich die p-Selektion einen sehr guten Lernerfolg hat mit Precision > 0,95, für die anderen drei Methoden ist die Precision < 0,4.
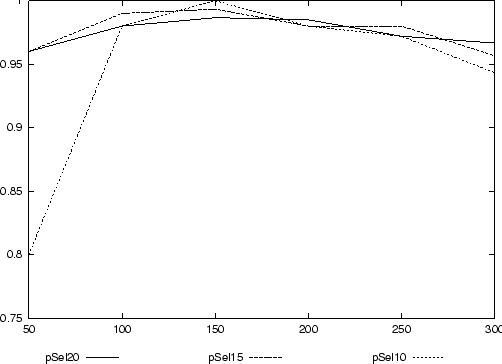
Aufgrund des guten Lernerfolgs der p-Selektion mit p=20 bietet es sich an dieser Stelle an, zu ermitteln, welcher Wert für p optimal ist. Zu diesem Zweck wird die Klassifikation mit vorheriger p-Selektion für p=15 und p=10 durchgeführt.
Für die p-Selektion stellt sich, wie in Abbildung 9 zu sehen, heraus, daß die Alternierung von p zu keinen großen Unterschieden bei der Klassifikation führt. Es ist lediglich zu beobachten, daß die p-Selektion mit p=10 bei 50 Trainingsdaten ein verhältnismäßig schlechtes Klassifikationsergebnis erzielt. Dies ist dadurch zu erklären, daß bei niedriger Anzahl von Trainingsdokumenten ein schlechteres Verhältnis von ,,Quasi-Stopworten`` zu bedeutungstragenden Features angenommen werden kann, weshalb die mit 10% an weggelassenen Features gewählte Schranke sehr wahrscheinlich einen Teil dieser ,,Quasi-Stopworte`` nicht ,,wegschneidet``. Weiterhin stellt sich an dieser Stelle die Frage, ob die mehrdeutige Klassen-Zuordnung durch die IMDb auch die ,,Trainingsqualität`` beeinflußt.