In diesem ersten Experiment wird die Klassifikation zunächst für die Zuordnung von Filmen zu Genres nach dem Schema der IMDb überprüft. Die zu unterscheidenden Klassen sind also nicht disjunkt.
Zunächst wird folgendes vergleichende Experiment gemacht:
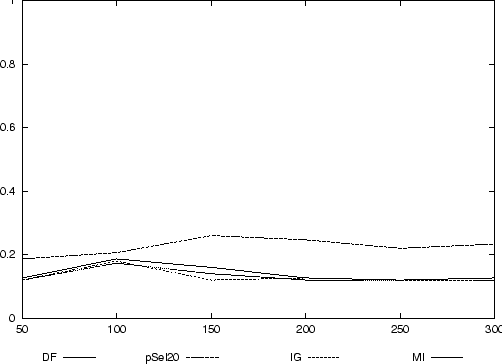
Dabei wird die Anzahl an Trainingsdaten mit 50 beginnend bis 300 in 50er Schritten erhöht. Der Klassifikator wird mit den Trainingsdaten trainiert, und anschließend werden die 150 Dokumente der Testdaten klassifiziert.
In Abbildung 4 ist zu sehen, daß die Precision dieser Experimente außerordentlich niedrig ist. Weiterhin zeigt sich, daß die Klassifikation nach der p-Selektion sehr viel bessere Ergebnisse erreicht als die Klassifikation nach der Feature-Selektion durch die anderen drei Methoden. Bemerkenswert ist weiterhin, daß sich die Klassifikationsqualität auch mit zunehmender Anzahl von Trainingsdaten nicht verbessert.
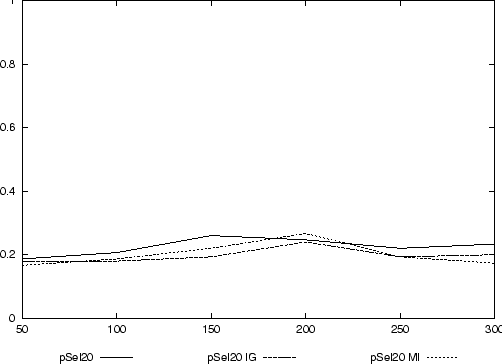
Das nächste Experiment soll nun überprüfen, ob die Klassifikationsqualität durch eine Kombination aus p-Selektion und Information Gain bzw. Mutual Information verbessert werden kann. Zu diesem Zweck werden 2000 Features durch p-Selektion vorselektiert, die anschließend mit Hilfe von Information Gain und Mutual Information jeweils auf 1000 Features reduziert werden. Mit diesen Features aus 50, 100, ..., 300 Trainingsdaten wird der Klassifikator jeweils trainiert und die 150 Testdokumente klassifiziert.
Abbildung 5 zeigt das Ergebnis der kombinierten Klassifikation im Vergleich mit dem besten Ansatz der p-Selektion von 1000 Features aus der vorhergehenden Testreihe. Bei der Qualität der Klassifikation ist kein nennenswerter Unterschied zwischen den verschiedenen Methoden festzustellen.
In den beiden Teilexperimenten dieses Abschnitts hat sich herausgestellt, daß für die Trainingsdaten und die Zuordnung von Filmen zu Genres nach dem Schema der IMDb keine guten Klassifikationsergebnisse erreicht werden. Ein möglicher Grund für dieses schlechte Ergebnis könnte hierbei die Tatsache sein, daß die Klassen nicht disjunkt sind und somit eine Unterscheidung der Klassen sehr viel schwieriger zu erreichen ist. Eine weitere Ursache für die niedrige Precision könnte der Klassifikator sein, der für diese Datenmenge eventuell ungeeignet ist. Im folgenden wird zunächst der Frage nach dem Einfluß der mehrdeutigen Zuordnung von Dokumenten zu Klassen nach der IMDb nachgegangen.