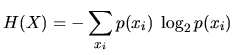Eine primäre Schwierigkeit der Klassifikation ist die hohe Dimensionalität des Feature-Raums (vgl. [YP97]). Schon für relativ kleine Mengen von Trainingsdokumenten kann die Anzahl an verschiedenen Features (der die Dimension des Feature-Raums entspricht) 5-stellige oder sogar 6-stellige Werte annehmen. Da die Laufzeit der meisten Algorithmen zur automatischen Klassifikation von dieser Anzahl an Features abhängt, ist es also wünschenswert, die Anzahl an Features zu reduzieren. Dabei sollten jedoch nach Möglichkeit nur Features mit geringem oder keinem Informationsgehalt entfernt werden, während sehr informative Features gehalten werden sollten.
Um eine Reduktion von Features zu erreichen, ist es also notwendig, diese Features bezüglich ihres Informationsgehaltes zu bewerten. Für eine solche Bewertung ist die Betrachtung
Für die Bewertung von Features bezüglich ihres Informationsgehaltes lassen sich verschiedene Maße verwenden, von denen hier folgende betrachtet werden:
Weitere Maße zur Feature-Selektion sind z. B. ![]() und term strength, die hier jedoch nicht
weiter betrachtet werden.
und term strength, die hier jedoch nicht
weiter betrachtet werden.
Bei der Berechnung von Information Gain und Mutual Information werden einige Wahrscheinlichkeiten von Klassen und Features verwendet, die an dieser Stelle kurz definiert werden sollen:
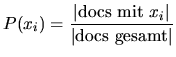
![]() ist entsprechend
ist entsprechend ![]()
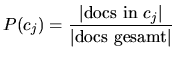

![]()

Grundlage für die Berechnung von Information Gain und Mutual Information ist die Information I eines Ereignisses x:
Das übliche Maß des Informationsgehaltes einer Zufallsvariablen X mit Ereignissen ![]() ist deren
(Shannon-)Entropie, die sich über
ist deren
(Shannon-)Entropie, die sich über ![]() definieren läßt als (vgl. [Sha48]):
definieren läßt als (vgl. [Sha48]):