Die ,,Distanz`` zwischen zwei Wahrscheinlichkeitsverteilungen p und q kann durch ihre relative Entropie gemessen werden:
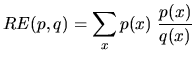
Mutual Information ist die relative Entropie zwischen der Wahrscheinlichkeit zweier Variablen
![]() und dem Produkt ihrer einzelnen Wahrscheinlichkeiten
und dem Produkt ihrer einzelnen Wahrscheinlichkeiten
![]() :
:
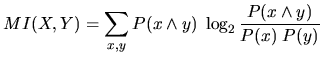
Mit Mutual Information wird der Informationsgehalt gemessen, über den die beteiligten Wahrscheinlichkeitsverteilungen wechselseitig (mutual) verfügen.
Im Kontext der Klassifikation für Features ![]() und Klassen
und Klassen ![]() ist deren Mutual Information
ist deren Mutual Information
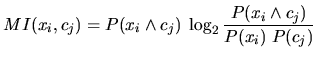
Für die Selektion eines Features ![]() werden die MI Werte für alle Klassen
werden die MI Werte für alle Klassen ![]() gewichtet nach deren
Wahrscheinlichkeit
gewichtet nach deren
Wahrscheinlichkeit ![]() summiert:
summiert:
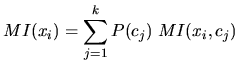
Für die Entscheidung zwischen k Klassen
![]() werden diejenigen Features
werden diejenigen Features ![]() ausgewählt, für die
ausgewählt, für die ![]() am größten ist.
am größten ist.