Der Informationsgewinn IG eines Features ![]() ist definiert als:
ist definiert als:
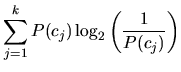 |
|||
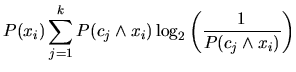 |
|||
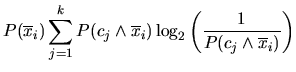 |
Für die Entscheidung zwischen k Klassen
![]() werden die Features
werden die Features ![]() mit dem
größten Wert für
mit dem
größten Wert für ![]() ausgewählt.
ausgewählt.
Durch den Informationsgewinn wird für jedes Feature ![]() ermittelt, wieviel Information für die
Unterscheidung zwischen verschiedenen Klassen gewonnen wird oder verloren geht, wenn dieses Feature
weggelassen wird (vgl. [YP97]).
ermittelt, wieviel Information für die
Unterscheidung zwischen verschiedenen Klassen gewonnen wird oder verloren geht, wenn dieses Feature
weggelassen wird (vgl. [YP97]).