Diese noch relativ junge Methode wurde 1995 von Vapnik eingeführt [Vap95] und von Joachims für die automatische Klassifikation mit Trainingsdaten erstmals verwendet [Joa98].
Gesucht wird hierbei die Hyperebene (auch Entscheidungsgrenze (decision boundary)
[DC00] oder Entscheidungsfläche (decision surface) [YL99] genannt)
![]() , die diejenigen Trainingsdokumente, die in eine Klasse c eingeordnet sind,
von den Trainingsdokumenten, die nicht in dieser Klasse enthalten sind, optimal trennt. Optimal bedeutet
hierbei, daß der euklidische Abstand aller Trainingsvektoren zu der Hyperebene maximiert werden soll.
, die diejenigen Trainingsdokumente, die in eine Klasse c eingeordnet sind,
von den Trainingsdokumenten, die nicht in dieser Klasse enthalten sind, optimal trennt. Optimal bedeutet
hierbei, daß der euklidische Abstand aller Trainingsvektoren zu der Hyperebene maximiert werden soll.
![]() ist der Feature-Vektor des zu klassifizierenden Dokuments, der Vektor
ist der Feature-Vektor des zu klassifizierenden Dokuments, der Vektor ![]() und die Konstante
b werden über das Training der Beispieldokumente bestimmt.
und die Konstante
b werden über das Training der Beispieldokumente bestimmt.
Für eine Menge von bereits klassifizierten Trainingsdokumenten
![]() mit
mit
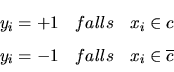
kann das Problem der Abstandsmaximierung als Optimierungsproblem wie folgt ausgedrückt werden:
Minimiere
![]()
unter Nebenbedingung, daß
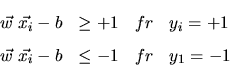
Die Vektoren, die genau den Abstand
![]() von der Hyperebene haben, werden Stützvektoren
genannt. Die trennende Hyperebene wird ausschließlich von diesen Vektoren bestimmt, so daß die gleiche
Hyperebene bestimmt wird, wenn alle anderen Trainingsdaten entfernt würden.
von der Hyperebene haben, werden Stützvektoren
genannt. Die trennende Hyperebene wird ausschließlich von diesen Vektoren bestimmt, so daß die gleiche
Hyperebene bestimmt wird, wenn alle anderen Trainingsdaten entfernt würden.
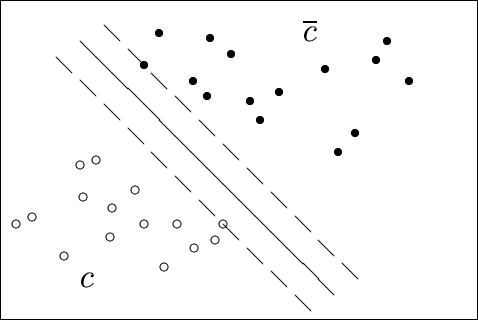
Die Abbildungen 2 und 3 illustrieren die Maximierung des Abstandes für ein Beispiel im 2-dimensionalen Raum, in dem die Hyperebene eine Linie ist.
Die durchgezogenen Linien in den Abbildungen sind mögliche trennende Linien zwischen den Dokumenten der
Mengen c und
![]() , die gestrichelten Linien geben den ,,Rand`` der jeweiligen
Dokumentenmenge wieder, dessen Abstand zur Trennlinie genau
, die gestrichelten Linien geben den ,,Rand`` der jeweiligen
Dokumentenmenge wieder, dessen Abstand zur Trennlinie genau
![]() beträgt. Die auf dieser
Randlinie (bzw. Rand-Hyperebene im mehrdimensionalen Fall) liegenden Vektoren sind also die Stützvektoren.
beträgt. Die auf dieser
Randlinie (bzw. Rand-Hyperebene im mehrdimensionalen Fall) liegenden Vektoren sind also die Stützvektoren.
Natürlich sind die Mengen von positiven und negativen Beispielen für eine Klasse nicht immer linear zu separieren, wie es im gezeigten Beispiel der Fall ist. Hierfür muß ,,erlaubt`` werden, daß sich Trainings-Dokumente auf der falschen Seite der Entscheidungsgrenze befinden. Dafür werden ,,Schlupfvariablen`` in den entsprechenden Nebenbedingungen eingeführt, die dies jedoch gleichzeitig ,,bestrafen`` (vgl. [DC00]).