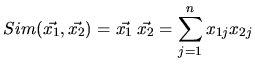Die k-Nearest-Neighbor-Klassifikation basiert auf der Ähnlichkeit von Dokumenten bzw. der Ähnlichkeit ihrer
Dokumentenvektoren. Für ein zu klassifizierendes Dokument d werden die k nächsten
Nachbarn bezüglich eines Ähnlichkeitsmaßes gesucht, die die Basis für die Klassifikation bilden.
Über die Verteilung der Zugehörigkeit dieser k nächsten Nachbarn zu den verschiedenen
Klassen ![]() wird d in die Klasse eingeordnet, für die die Funktion
wird d in die Klasse eingeordnet, für die die Funktion
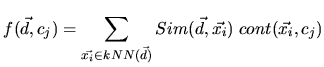
maximal wird, wobei
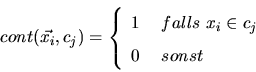
![]() ist das Maß der Ähnlichkeit zwischen den Dokumenten d und
ist das Maß der Ähnlichkeit zwischen den Dokumenten d und ![]() , jeweils
repräsentiert durch ihren Feature-Vektor. (Es wird an dieser Stelle davon ausgegangen, daß der Feature-Raum
n Dimensionen hat und jeder Feature-Vektor gleich lang ist.) Für die Ähnlichkeit bieten sich nun
zum Beispiel folgende Maße an:
, jeweils
repräsentiert durch ihren Feature-Vektor. (Es wird an dieser Stelle davon ausgegangen, daß der Feature-Raum
n Dimensionen hat und jeder Feature-Vektor gleich lang ist.) Für die Ähnlichkeit bieten sich nun
zum Beispiel folgende Maße an:
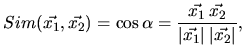
wobei ![]() der Winkel zwischen den beiden Vektoren ist.
der Winkel zwischen den beiden Vektoren ist.
Für normalisierte Vektoren
![]() mit
mit
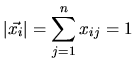
läßt sich die Cosinus-Ähnlichkeit als Produkt der Vektoren schreiben: