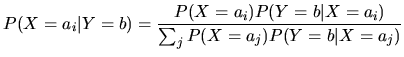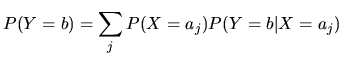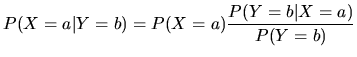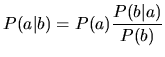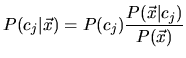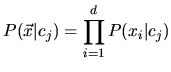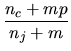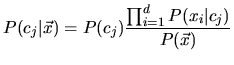Basis für die automatische Klassifikation nach dem Naive-Bayes-Verfahren sind zwei zentrale Sätze der Wahrscheinlichkeitsrechnung:
Einsetzen von (2) in (1) und eine Umbenennung von ![]() in a
ergibt:
in a
ergibt:
Zur Vereinfachung und Erhöhung der Lesbarkeit werden Wahrscheinlichkeitsverteilungen ![]() von
Variablen X mit möglichen Ereignissen
von
Variablen X mit möglichen Ereignissen ![]() geschrieben als
geschrieben als ![]() , so daß sich (3)
schreibt als:
, so daß sich (3)
schreibt als:
Das Klassifikationsproblem stellt sich im Fall der Naive-Bayes-Klassifikation als die Wahrscheinlichkeit,
daß ein Dokument, repräsentiert durch einen Featurevektor
![]() im
d-dimensionalen Feature-Raum, in die Klasse
im
d-dimensionalen Feature-Raum, in die Klasse ![]() einzuordnen ist. (Hierbei wird davon ausgegangen,
daß jedes Dokument durch einen Featurevektor der Länge d dargestellt werden kann.) Gesucht wird
also die bedingte Wahrscheinlichkeit
einzuordnen ist. (Hierbei wird davon ausgegangen,
daß jedes Dokument durch einen Featurevektor der Länge d dargestellt werden kann.) Gesucht wird
also die bedingte Wahrscheinlichkeit
![]() . Mit (4) ergibt sich somit:
. Mit (4) ergibt sich somit:
Wenn alle
![]() bekannt sind, kann ein Dokument mit Featurevektor
bekannt sind, kann ein Dokument mit Featurevektor ![]() mit minimierter
Fehlererwartung in die Klasse
mit minimierter
Fehlererwartung in die Klasse ![]() eingeordnet werden, für die
eingeordnet werden, für die
![]() den größten Wert annimmt
(vgl. [Lew98]). Da
den größten Wert annimmt
(vgl. [Lew98]). Da
![]() jedoch in der Regel nicht bekannt ist, muß an dieser Stelle
auf den Ansatz zurückgegriffen werden, den (5) nahelegt. Hierbei läßt sich
jedoch in der Regel nicht bekannt ist, muß an dieser Stelle
auf den Ansatz zurückgegriffen werden, den (5) nahelegt. Hierbei läßt sich ![]() bei n Trainingsdokumenten leicht berechnen als
bei n Trainingsdokumenten leicht berechnen als
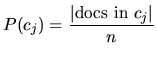
![]() wird hierbei oft abgeschätzt durch
wird hierbei oft abgeschätzt durch
wobei ![]() die Anzahl der Vorkommen des Features
die Anzahl der Vorkommen des Features ![]() in den zu
in den zu ![]() gehörenden Dokumenten und
gehörenden Dokumenten und
![]() die Anzahl der Features in den zu
die Anzahl der Features in den zu ![]() gehörenden Dokumenten ist. Diese Abschätzung stellt
sich jedoch als problematisch heraus, wenn
gehörenden Dokumenten ist. Diese Abschätzung stellt
sich jedoch als problematisch heraus, wenn ![]() , da als Folge dessen auch die Abschätzung von
, da als Folge dessen auch die Abschätzung von
![]() nach (6) den Wert 0 annähme. Um diesen Fall zu vermeiden, bietet
sich die Verwendung des m-estimate (vgl. [Mit97]) an, das definiert ist als:
nach (6) den Wert 0 annähme. Um diesen Fall zu vermeiden, bietet
sich die Verwendung des m-estimate (vgl. [Mit97]) an, das definiert ist als:
Hierbei sind ![]() und
und ![]() definiert wie zuvor, p ist die initiale Abschätzung der zu
ermittelnden Wahrscheinlichkeit und
definiert wie zuvor, p ist die initiale Abschätzung der zu
ermittelnden Wahrscheinlichkeit und ![]() eine Konstante, genannt equivalent sample size, die
bestimmt, wie stark p relativ zu den trainierten Daten gewichtet wird. Sie heißt deshalb
equivalent sample size, weil (7) interpretiert werden kann als Erweiterung der
eine Konstante, genannt equivalent sample size, die
bestimmt, wie stark p relativ zu den trainierten Daten gewichtet wird. Sie heißt deshalb
equivalent sample size, weil (7) interpretiert werden kann als Erweiterung der
![]() Features in
Features in ![]() um m virtuelle Features, die p entsprechend verteilt sind
[ebd.].
um m virtuelle Features, die p entsprechend verteilt sind
[ebd.].
Mit (6) ergibt sich weiterhin folgende Form zur Berechnung von
![]() :
:
Einen Klassifikator, der auf der Basis von (8) ein Dokument, das durch einen
Featurevektor ![]() repräsentiert wird, der Klasse
repräsentiert wird, der Klasse ![]() zuordnet, für die
zuordnet, für die
![]() den
höchsten Wert annimmt, nennt man einen Naive-Bayes-Klassifikator (vgl. [Lew98]). Zur
Vereinfachung der Berechnung kann außerdem
den
höchsten Wert annimmt, nennt man einen Naive-Bayes-Klassifikator (vgl. [Lew98]). Zur
Vereinfachung der Berechnung kann außerdem
![]() vernachlässigt werden, da diese Wahrscheinlichkeit
für alle Klassen
vernachlässigt werden, da diese Wahrscheinlichkeit
für alle Klassen ![]() gleich ist; als Maß für die Klassifikation kann also
gleich ist; als Maß für die Klassifikation kann also
![]() verwendet werden.
verwendet werden.
,,Naiv(e)`` ist bei diesem Klassifikator die Annahme, die Schritt 6 zugrunde liegt.
Dieser Schritt basiert nämlich auf der Annahme, daß das Vorkommen eines Wertes ![]() statistisch
unabhängig von Vorkommen aller anderen
statistisch
unabhängig von Vorkommen aller anderen ![]() ist (vgl. [Yan99]).
ist (vgl. [Yan99]).