Übliche Information Retrieval-Systeme (wie z. B. die meisten Suchmaschinen im World Wide Web) beschäftigen
sich hauptsächlich mit der Beantwortung von Anfragen auf der Grundlage einer indexierten Dokumentenmenge.
Auf dieser Basis läßt sich grundsätzlich jede Anfrage mit einer Menge (mitunter auch der leeren
Menge ![]() ) von Dokumenten beantworten.
) von Dokumenten beantworten.
Eine Möglichkeit, auf andere Art und Weise Informationen über eine Dokumentenmenge zur Verfügung zu
stellen, besteht darin, diese Dokumentenmenge in einer hierarchischen Ontologie zu gliedern. Unter einer
hierarchischen Ontologie versteht man im Kontext des Information Retrieval eine Baum- bzw. Graphstruktur mit
verschiedenen Themengebieten als Knoten ![]() und gerichteten Kanten
und gerichteten Kanten ![]() , wobei
, wobei ![]() das Oberthema
zu
das Oberthema
zu ![]() ist. Dies beinhaltet insbesondere, daß der Graph zykelfrei ist.
ist. Dies beinhaltet insbesondere, daß der Graph zykelfrei ist.
Gibt es in diesem Graphen Kanten ![]() und
und ![]() mit j=l (also Klassen, die mehrere
Oberklassen haben), so spricht man von einer polyhierarchischen Ontologie, ist dies nicht der Fall, so ist
die Ontologie monohierarchisch.
mit j=l (also Klassen, die mehrere
Oberklassen haben), so spricht man von einer polyhierarchischen Ontologie, ist dies nicht der Fall, so ist
die Ontologie monohierarchisch.
Als Problem bei hierarchischen Ontologien stellt sich oft die Dimensionalität dar, da die Einteilung einer Klasse in Unterklassen aufgrund verschiedener Merkmale erfolgen kann, wobei diese Merkmale unter Umständen orthogonal zueinander sind (vgl. [Fuh93]). Ein Beispiel hierfür wäre die Einteilung von Unternehmen einerseits nach Art des Gewerbes, andererseits nach Regionen.
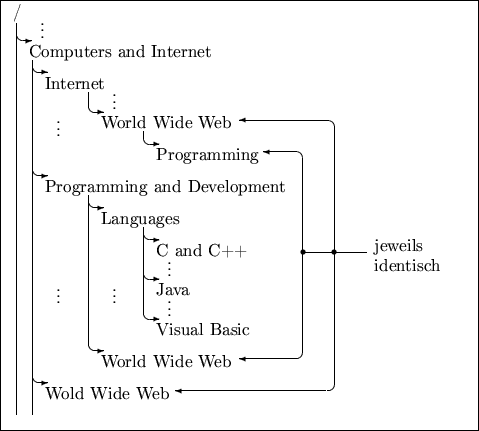
Hierarchische Ontologien werden für Dokumente des World Wide Web unter anderem von den Portalen von Yahoo oder Google bereitgestellt. Als Beispiel für eine solche Ontologie findet sich in Abbildung 1 ein Auszug aus dem Yahoo! Directory [Yah]. Der Wurzelknoten der Ontologie wird hierbei mit ,,/`` bezeichnet.
Bei dem vorliegenden Beispiel handelt es sich um eine polyhierarchische Ontologie, da die Klassen
Vorteilhaft bei hierarchischen Ontologien ist die Tatsache, daß gesuchte Informationen statisch - ohne weitere Rechenzeit - verfügbar sind. Weiterhin bietet die formale Struktur, die der Ontologie zugrunde liegt, eine intuitive Basis für die hierarchische Suche nach Informationen, was insbesondere auch dadurch bedingt ist, daß verschiedene Pfade zum selben Zielknoten führen, wie es im Beispiel der Fall ist.
Im Verlauf des Wachstums einer Ontologie ist es jedoch möglich, daß sich die zugrunde liegende formale Struktur als unbalanciert herausstellt. Dies ist der Fall, wenn neu hinzugefügte Dokumente sich an manchen Knoten konzentrieren, während andere Knoten nur schwach besetzt bleiben, so daß zumindest in Teilen der Ontologie nicht mehr von einer Strukturierung von Information gesprochen werden kann. Die Lösung dieses Problems besteht in der Regel darin, den betroffenen ,,überfüllten`` Knoten in Unterklassen aufzuspalten und die zugehörenden Dokumente auf diese neuen Klassen aufzuteilen, sofern sie nicht weiterhin diesem Knoten zugeordnet sein sollen. Eine weitere Möglichkeit wäre es natürlich, eine neue formale Struktur zu entwickeln, was jedoch ungleich aufwendiger ist, da dies eine komplett neue Zuordnung der vorhandenen Dokumente bedeuten würde.
An dieser Stelle zeigt sich deutlich, daß das Erstellen und die Pflege einer solchen Ontologie bedarf einigen intellektuellen Aufwandes, da die einzelnen Dokumente der Dokumentenmenge in die Klassen der Ontologie eingeordnet werden müssen. Um diesen Aufwand - insbesondere auf Dauer - gering zu halten, bedient man sich der automatischen Klassifikation.