Figure 1: Order Processing System for Online Merchandising
by Eric Armstrong
for Sun Microsystems, Inc.
XML Data Binding for the JavaTM 2 Platform aims to automatically generate substantial portions of the Java platform code that processes XML data. Data binding applications will be small and fast, suitable for server-side applications and other applications where processing efficiency is paramount. And, since the Java platform is vendor-neutral, those applications will run anywhere.
The data binding specification is currently being developed by an expert group of industry leading XML vendors through the Java Community Process -- the formalization of the open process that Sun has been using since 1995 to develop and revise Java technology specifications in cooperation with the international Java community. The project, code named "Adelard" was initiated by Sun in order to maximize the efficiency of XML-processing applications -- especially those with strict requirements for data validation.
With XML data binding, XML schema definitions (which dictate data structures and place restrictions on data contents) are automatically translated into Java classes. The generated classes then do the work of parsing the XML code, building the internal data structures, and validating data contents. These classes are "lightweight" in the sense that they carry no unnecessary functionality. As a result, data binding applications will use a minimum amount of memory and run as efficiently as possible. The use of data binding, coupled with high-performance virtual machines like the Java HotSpotTM Virtual Machine, makes it possible to deliver and maintain high-performance XML-processing applications with a minimum of development effort.
This paper provides background information on schemas and gives a conceptual overview of the data binding process. It also gives you an overview of the other major XML-processing mechanisms, SAX and DOM, so you know where data binding fits in the XML landscape.
"Deliver and maintain high-performance XML-processing applications with a minimum of development effort."
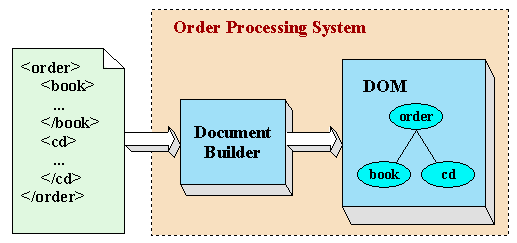
To motivate the discussion, let's assume that we're developing an online order processing application for the Amazing Book Co. (ABC) a semi-fictitious merchandising firm that is selling products over the web. The goal is to build an order-processing application like the one shown here:
Figure 1: Order Processing System for Online Merchandising
In this example, the order taking system could be a server application or a client-side application. It encodes the purchaser's order in XML and sends it to the order-processing server, which may route shipping requests (again, encoded in XML) to a remote warehouse. For some products, the "warehouse" might be a third-party manufacturer that fills orders on demand. In such cases, the XML format for data transmission may become virtually mandatory as we move forward into the next century.
The order processing server might check on product availability, reserve product for shipment, and check the purchaser's credit card before sending out one or more shipping requests. For the moment, though, we can ignore those details. The important issue for our discussion is how the order, encoded in XML, is converted into data that the server application can operate on.
Currently, there are two major mechanisms for dealing with XML data and documents: SAX and DOM. As you will see, neither is completely appropriate for our order-processing application.
For high-speed processing of XML, the usual choice is the Simple API for XML (SAX). This mechanism processes XML data like a text stream and alerts the application whenever something interesting comes along. When an application uses SAX, it gets alerts like "here's an <ORDER> element", or "here is some text". A SAX-based application takes little memory, and it tends to be fast because it is not creating an in-memory copy of the data -- it is simply reacting to things, one at a time, as they come along.
Although SAX is appropriate for a large class of applications, the lack of an in-memory data structure is a major downside for applications like our order-processing example. Having all of the ordered items in memory can make it easier to calculate and adjust totals or group similar items together. In addition, SAX does not include mechanisms for writing out XML. It is a read-only system. So SAX provides only limited benefits for our order processing application.
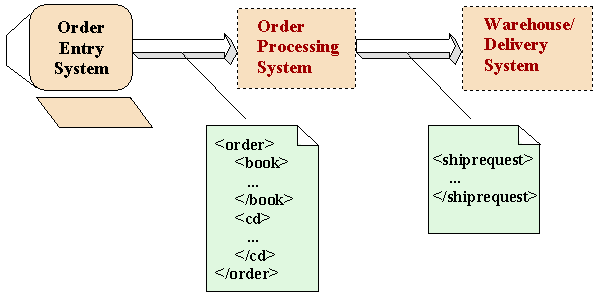
For an application that needs an in-memory data structure, the Document Object Model (DOM) presents a useful alternative. To use a DOM, the application takes advantage of a document builder, which reads the XML data and then constructs a DOM, as shown here:
Figure 2: Order Processing System with DOM
Once the DOM has been constructed, the application can manipulate it in a variety of ways. The application can add elements, remove them, shift them around, or change their contents. With a single command, it can then easily write out the resulting data structure as XML.
However, much of that flexibility is superfluous for the order processing application. In all likelihood, for example, such an application will not need to move elements around. The bottom line is that DOM, the Document Object Model, was intended for documents. It is a powerful tool for managing even very large documents, especially those in which large amounts of text are mixed in with the markup tags as you find, for example, in an HTML document.
For an order-processing application, though, DOM's flexibility is not needed. Worse, the additional overhead required to implement that functionality adds to the memory footprint of the application and detracts from its speed. So DOM is not really appropriate for our order processing application, either.
Before we move on to a discussion of data binding's benefits for applications like our server-side order processing example, we need to understand the vital role that schemas play in the world of XML data.
The schema concept comes from database systems. A schema tells the database system how the data is structured, and what kinds of data are valid. For example, it might tell a personnel system that an employee record contains an employee number, a name, address, title, and salary. The schema definition allows for automated data checking, known as data validation. For example, it allows the database to make sure that the employee's salary is greater than the current minimum wage and less than some maximum determined by the employee's title. A schema also allows the database to make sure that certain critical fields are filled out while others (like multiple address lines) can reasonably be left blank.
In the world of XML, it has (until recently) been largely impossible to specify such data restrictions for XML data sets. When XML first came on the scene, it arrived with the capacity to specify a Data Type Definition (DTD), which was derived from XML's parent, the Standardized General Markup Language (SGML). However, while DTD specifications allow the validation of data structure, they did not allow the validation of data content.
In our order entry example, for instance, a DTD can specify that an <order> consists of <book> and <cd> elements only. The automatic validation mechanisms that are part of SAX and DOM can then determine that an order which contains a <shoe> element is invalid, and the order can be rejected.
Because SAX and DOM have only been dealing with DTD specifications up until now, they have only performed structure validation -- a fraction of the processing that full content validation implies. To go beyond data structure and validate data content, a schema is needed. The currently coalescing w3c XML Schema standard makes content validation possible, as do other schema languages like SOX, XDR, and DSD.For commercial applications, content validation often constitutes a major portion of the application. For example, the definition for a credit card field can specify that the data consists of 16 digits. The field, might allow 16 digits in a row, or 4 groups of 4 digits all separated by spaces, or the same grouping separated by hyphens. Some cards may introduce additional restrictions, as well. One card might disallow zeroes in certain locations. Another might stipulate that some digits are derived from the expiration date, as an additional check on the validity of the card number. It can take a fair amount of coding and testing to get all the data checks just right. That adds up to more development time and higher development costs.
In addition, content validation represents a high-maintenance part of the code, since data-validation standards often change. For example, the maximum salary for a given position tends to go up every few years. With manual coding, each such change requires human intervention, often in more than one application. But the existence of an XML schema makes it possible to automatically generate the code required for content validation.
If content validation can be automated, as well as structure validation, then application development times can be reduced,along with the cost of ongoing maintenance. But the cost of doing automatic validation using SAX and DOM figures to be somewhat higher than doing the same job with data binding.
The reason for the higher cost in SAX and DOM is that the schema must be interpreted as the XML data is being read. It requires a substantial amount of code to implement a general purpose content-validation mechanism. While many efforts are underway today to eke out the maximum possible performance, the fact remains that real time interpretation of the schema must of necessity take somewhat longer than precompiled logic.
Not all applications need maximal performance, though. And not all applications need highly restrictive content validation. For example, an application that is reading a small configuration file it wrote itself has little need for content-validation overhead. A SAX parser would be perfectly adequate, and would keep the application small. On the other hand, a bona-fide document tends to have severe restrictions on structure (all references at the end of a chapter, for example, and they must contain an author, title, and page number), but has very little need for content validation (no document processor cares what the author's name is.)
SAX and DOM remain appropriate, then, for applications that are not spending sizable proportions of their time doing content validation . But for those applications that require data validation, and which require it to be performed efficiently, data binding offers the perfect alternative.
"For those applications that require data validation, and which require it to be performed efficiently, data binding offers the perfect alternative."
The data binding facility promises to significantly improve the performance and functionality of server-based programs and other high-performance applications that process XML, while at the same time reducing both development and maintenance costs.
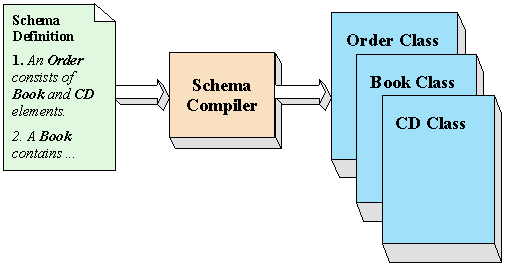
In essence, data binding operates by "compiling" a schema specification to produce Java classes, as shown here:
Figure 3: Compiling a Schema to Create Class Definitions
The generated classes include the code required to validate data content as well as data structure, thus relieving the programmer from the necessity of doing so. Since the minimum of code needed to accomplish validation is generated, and that code is compiled, it will tend to take less space and run many times faster than could possibly occur if a SAX or DOM application were to attempt similarly automated content validation.
When the schema changes, simply recompiling it changes the application. So maintenance is reduced, as well as the original programming effort. Finally, the generated application runs with a speed comparable to that of a SAX application, yet it builds an in-memory data structure like a DOM, and without the additional overhead intrinsic to a DOM. For applications like our server-side order-entry example, then, data binding is pretty close to perfect. (Well, you still have to write some code...)
At this point, you understand all that you need to know to discuss the advantages of data binding at a cocktail party. (Assuming you like talking to yourself). For the "techies" in the crowd, here two more topics that dive into a bit of additional detail:
"Just as XML "future proofs" your data, the Java platform "future proofs" your applications."
The Adelard project for XML Data Binding promises to significantly improve the performance and functionality of a wide base of server-based programs and other high-performance applications. Because it compiles a schema into Java code, it allows efficient validation of data content as well as data structure. In addition, the resulting applications are eminently portable. Just as XML "future proofs" your data by allowing you to change database servers or generate output in different formats, the Java platform "future proofs" your applications against hardware and operating system obsolescence.
© Sun Microsystems, Inc. All Rights Reserved. Sun, Sun Microsystems, Java, and HotSpot are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries.